

“Study finds that increased parental support for college results in lower grades” (Jaschik, 2013). “People with mental illness more likely to be smokers” (Belluck,2013).
What should we make of such news headlines-telling us that students whose parents pay the college bill tend to underachieve, and that smoking is associated with mental illness? Do these correlations indicate that students would achieve more if their parents became less supportive and that stopping smoking could produce better mental health? No. Read on.
What are positive and negative correlations, and why do they enable prediction but not cause-effect explanation?
Describing behavior is a first step toward predicting it. Naturalistic observations and surveys often show us that one trait or behavior is related to another. In such cases, we say the two correlate. A statistical measure (the correlation coefficient) helps us figure how closely two things vary together, and thus how well either one predicts the other. Knowing how much aptitude test scores correlate with school success tells us how well the scores predict school success.
Throughout this book we will often ask how strongly two things are related: For example, how closely related are the personality scores of identical twins? How well do intelligence test scores predict career achievement? How closely is stress related to disease? In such cases, scatterplots can be very revealing.
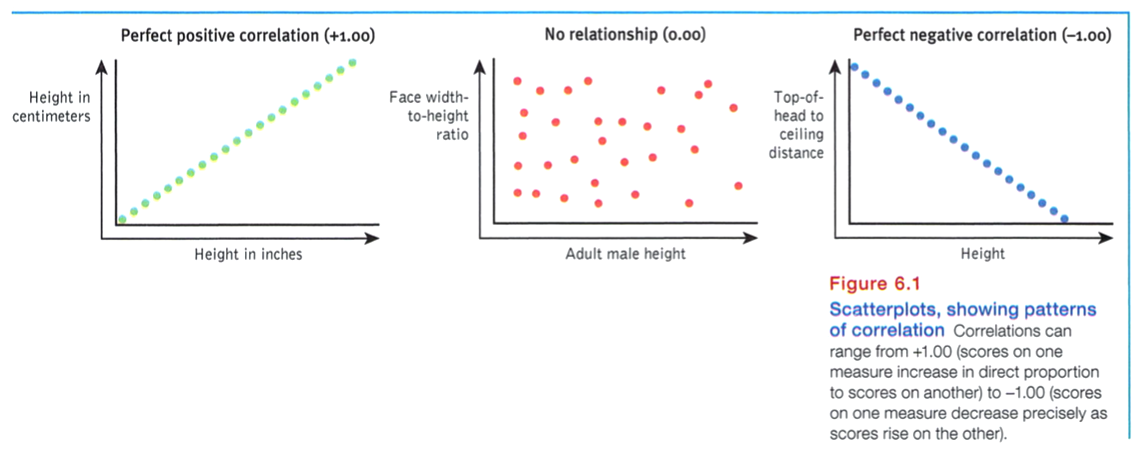
Each dot in a scatterplot represents the values of two variables. The three scatterplots in FIGURE 6.1 illustrate the range of possible correlations from a perfect positive to a perfect negative. (Perfect correlations rarely occur in the “real world.”) A correlation is positive if two sets of scores, such as height and weight, tend to rise or fall together.
Saying that a correlation is “negative” says nothing about its strength or weakness. A correlation is negative if two sets of scores relate inversely, one set going up as the other goes down. The study of Nevada university students’ inner speech discussed in Module 5 also included a correlational component. Students’ reports of inner speech correlated negatively (- .36) with their scores on another measure: psychological distress. Those who reported more inner speech tended to report slightly less psychological distress.
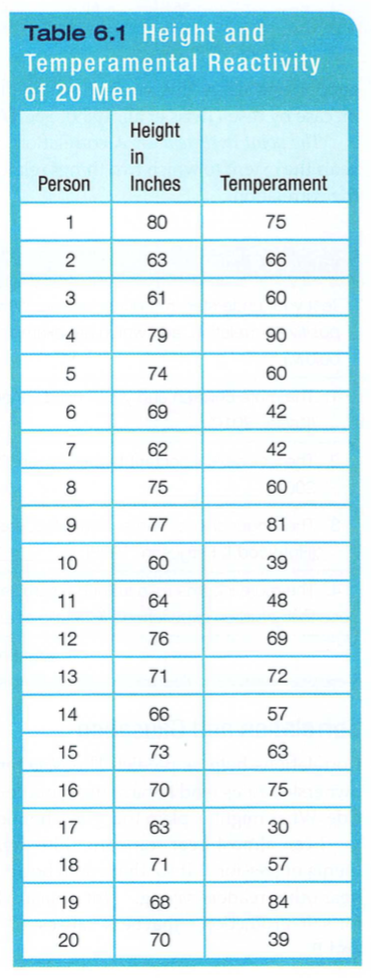
Statistics can help us see what the naked eye sometimes misses. To demonstrate this for yourself, try an imaginary project. Wondering if tall men are more or less easygoing, you collect two sets of scores: men's heights and men's temperaments. You measure the heights of 20 men, and you have someone else independently assess their temperaments (from zero for extremely calm to 100 for highly reactive).
With all the relevant data right in front of you (TABLE 6.1), can you tell whether the correlation between height and reactive temperament is positive, negative, or close to zero?
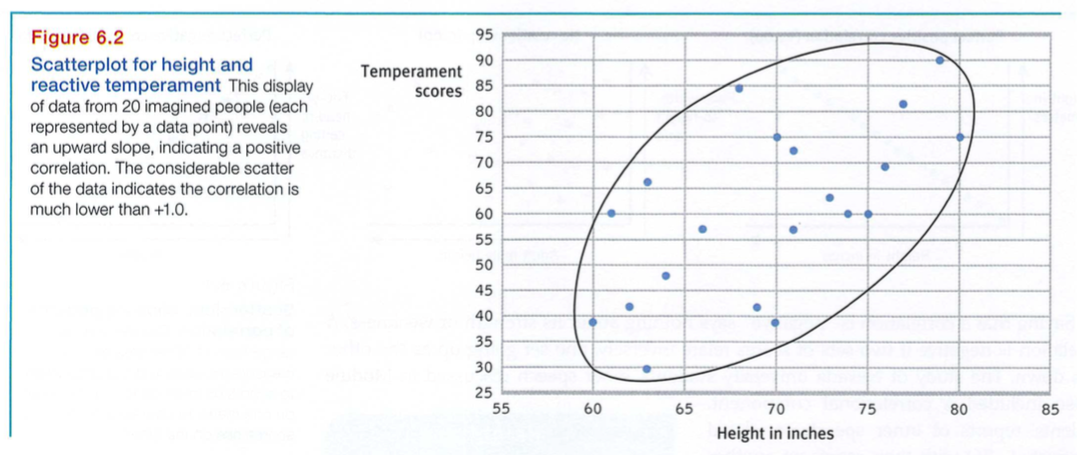
Comparing the columns in Table 6.1, most people detect very little relationship between height and temperament. In fact, the correlation in this imaginary example is positive, +0.63, as we can see if we display the data as a scatterplot. In FIGURE 6.2 on the next page, moving from left to right, the upward, oval-shaped slope of the cluster of points shows that our two imaginary sets of scores (height and temperament) tend to rise together.
If we fail to see a relationship when data are presented as systematically as in Table 6.1, how much less likely are we to notice them in everyday life? To see what is right in front of us, we sometimes need statistical illumination. We can easily see evidence of gender discrimination when given statistically summarized information about job level, seniority, performance, gender, and salary. But we often see no discrimination when the same information dribbles in, case by case (Twiss et a1., 1989). See TABLE 6.2 to test your understanding further. The point to remember: A correlation coefficient, which can range from -1.0 to +1.0, reveals the extent to which two things relate. The closer the score gets to –1 or +1, the stronger the correlation.
Correlations help us predict. The New York Times reports that U.S. counties with high gun ownership rates tend to have high murder rates (Luo, 2011). Gun ownership predicts homicide. What might explain this guns-homicide correlation?
I can almost hear someone thinking, “Well, of course, guns kill people, often in moments of passion.” If so, that could be an example of A (guns) causes B (murder). But I can hear other readers saying, “Not so fast. Maybe people in dangerous places buy more guns for self-protection-maybe B causes A” Or maybe some third variable C causes both A and B.
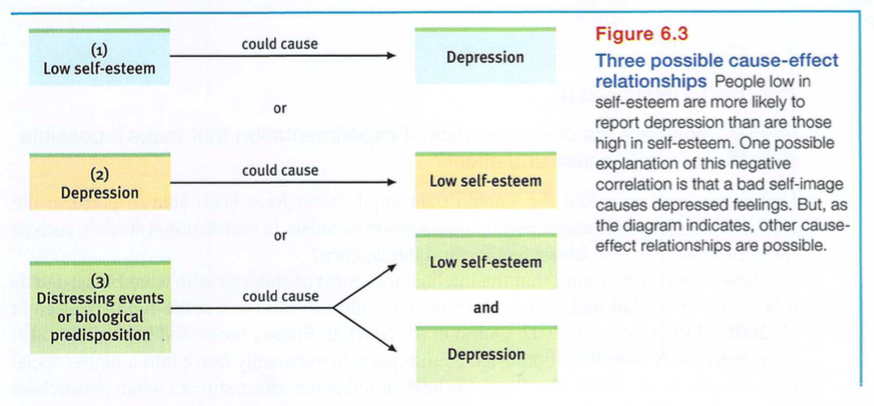
Another example: Self-esteem negatively with (and therefore predicts) depression. (The lower people’s self-esteem, the more they are at risk for depression.) So, does low self-esteem cause depression? If, based on the correlational evidence, you assume that it does, you have much company. A nearly irresistible thinking error is assuming that an association, sometimes presented as a correlation coefficient, proves causation. But no matter how strong the relationship, it does not.
As options 2 and 3 in FIGURE 6.3 show, we’d get the same negative correlation between self-esteem and depression if depression caused people to be down on themselves, or if some third variable-such as heredity or brain chemistry-caused both low self-esteem and depression.
This point is so important – so basic to thinking smarter with psychology – that it merits one more example. A survey of over 12,000 adolescents found that the more teens feel loved by their parents, the less likely they are to behave in unhealthy ways-having early sex, smoking, abusing alcohol and drugs, exhibiting violence (Resnick et a1., 1997). “Adults have a powerful effect on their children’s behavior right through the high school years,” gushed an Associated Press (AP) story reporting the finding. But this correlation comes with no built-in cause-effect arrow. The AP could as well have reported, “Wellbehaved teens feel their parents’ love and approval; out-of-bounds teens more often think their parents are disapproving jerks.”
A study reported in the British Medical Journal found that youths who identify with the goth subculture attempt, more often than other young people, to harm or kill themselves (Young et al., 2006). Can you imagine multiple possible explanations for this association?
What are illusory correlations?
Correlation coefficients make visible the relationships we might otherwise miss. They also restrain our “seeing” relationships that actually do not exist. A perceived but nonexistent correlation is an illusory correlation. When we believe there is a relationship between two things, we are likely to notice and recall instances that confirm our belief (Trolier & Hamilton, 1986).
Because we are sensitive to dramatic or unusual events, we are especially likely to notice and remember the occurrence of two such events in sequence-say, a premonition of an unlikely phone call followed by the call. When the call does not follow the premonition, we are less likely to note and remember the nonevent. Illusory correlations help explain many superstitious beliefs, such as the presumption that infertile couples who adopt become more likely to conceive (Gilovich, 1991). Couples who conceive after adopting capture our attention. We’re less likely to notice those who adopt and never conceive, or those who conceive without adopting. In other words, illusory correlations occur when we over-rely on the top left cell of FIGURE 6.4, ignoring equally essential information in the other cells.
Such illusory thinking helps explain why for so many years people believed (and many still do) that sugar makes children hyperactive, that getting chilled and wet causes people to catch a cold, and that changes in the weather trigger arthritis pain. We are, it seems, prone to perceiving patterns, whether they’re there or not.
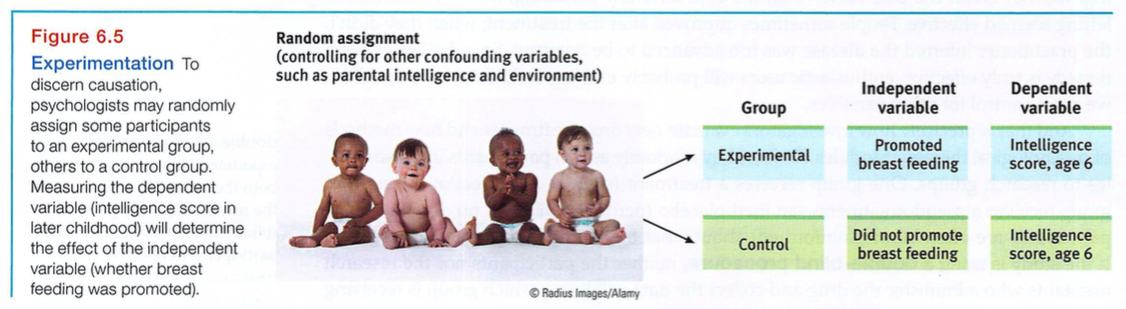
Happy are they, remarked the Roman poet Virgil, “who have been able to perceive the causes of things.” How might psychologists perceive causes in correlational studies, such as the correlation between breast feeding and intelligence?
Researchers have found that the intelligence scores of children who were breast-fed as infants are somewhat higher than the scores of children who were bottle-fed (Angelsen et al., 2001; Mortensen et al., 2002; Quinn et al., 2001). In Britain, breast-fed babies have also been more likely than their bottle-fed counterparts to eventually move into a higher social class (Martin et a1., 2007). The “breast is best” intelligence effect shrinks when researchers compare breast-fed and bottle-fed children from the same families (Der et al., 2006).
What do such findings mean? Do smarter mothers (who in modern countries more often breast feed) have smarter children? Or, as some researchers believe, do the nutrients of mother’s milk contribute to brain development? To find answers to such questions-to isolate cause and effect-researchers can experiment. Experiments enable researchers to isolate the effects of one or more variables by (1) manipulating the variables of interest and (2) holding constant (“ controlling”) other variables. To do so, they often create an experimental group, in which people receive the treatment, and a contrasting control group that does not receive the treatment.
Earlier we mentioned the place of random sampling in a well-done survey. Consider now the equally important place of random assignment in a well-done experiment. To minimize any preexisting differences between the two groups, researchers randomly assign people to the two conditions. Random assignment effectively equalizes the two groups. If one-third of the volunteers for an experiment can wiggle their ears, then about one-third of the people in each group will be ear wigglers. So, too, with ages, attitudes, and other characteristics, which will be similar in the experimental and control groups. Thus, if the groups differ at the experiment’s end, we can surmise that the treatment had an effect.
To experiment with breast feeding, one research team randomly assigned some 17,000 Belarus newborns and their mothers either to a breast-feeding promotion group or to a normal pediatric care program (Kramer et al., 2008). At 3 months of age, 43 percent of the infants in the experimental group were being exclusively breast-fed, as were 6 percent in the control group. At age 6, when nearly 14,000 of the children were restudied, those who had been in the breast-feeding promotion group had intelligence test scores averaging six points higher than their control condition counterparts.
No single experiment is conclusive, of course. But randomly assigning participants to one feeding group or the other effectively eliminated all variables except nutrition. This supported the conclusion that breast is indeed best for developing intelligence: If a behavior (such as test performance) changes when we vary an experimental variable (such as infant nutrition), then we infer the variable is having an effect.
Consider, then, how we might assess therapeutic interventions. Our tendency to seek new remedies when we are ill or emotionally down can produce misleading testimonies. If three days into a cold we start taking vitamin C tablets and find our cold symptoms lessening’ we may credit the pills rather than the cold naturally subsiding. In the 1700s, bloodletting seemed effective. People sometimes improved after the treatment; when they didn’t, the practitioner inferred the disease was too advanced to be reversed. So, whether or not a remedy is truly effective, enthusiastic users will probably endorse it. To determine its effect, we must control for other variables.
And that is precisely how investigators evaluate new drug treatments and new methods of psychological therapy (Modules 72-73). They randomly assign participants in these studies to research groups. One group receives a treatment (such as a medication). The other group receives a pseudotreatment – an inert placebo (perhaps a pill with no drug in it). The participants are often blind (uninformed) about what treatment, if any, they are receiving. If the study is using a double-blind procedure, neither the participants nor the research assistants who administer the drug and collect the data will know which group is receiving the treatment.
In such studies, researchers can check a treatment’s actual effects apart from the participants’ and the staff’s belief in its healing powers. Just thinking you are getting a treatment can boost your spirits, relax your body, and relieve your symptoms. This placebo effect is well documented in reducing pain, depression, and anxiety (Kirsch, 2010). And the more expensive the placebo, the more “real” it seems to us-a fake pill that costs $2.50 works better than one costing 10 cents (Waber et al, 2008). To know how effective a therapy really is, researchers must control for a possible placebo effect.
Here is a practical experiment: In a not yet published study, Victor Benassi and his colleagues gave college psychology students frequent in-class quizzes. Some items served merely as review – students were given questions with answers. Other self-testing items required students to actively produce the answers. When tested weeks later on a final exam, students did far better on material on which they had been tested (75 percent correct) rather than merely reviewed (51 percent correct). By a wide margin, testing beat restudy.
This simple experiment manipulated just one factor: the study procedure (reading answers versus self-testing). We call this experimental factor the independent variable because we can vary it independently of other factors, such as the students’ memories, intelligence, and age. These other factors, which can potentially influence the results of the experiment, are called confounding variables. Random assignment controls for possible confounding variables.
Experiments examine the effect of one or more independent variables on some measurable behavior, called the dependent variable because it can vary depending on what takes place during the experiment. Both variables are given precise operational definitions, which specify the procedures that manipulate the independent variable (the review versus self-testing study method in this analysis) or measure the dependent variable (final exam performance). These definitions answer the “What do you mean?” question with a level of precision that enables others to repeat the study. (See FIGURE 6.5 for the previously mentioned breast-milk experiment’s design.)
Let’s pause to check your understanding using a simple psychology experiment: To test the effect of perceived ethnicity on the availability of a rental house, researchers sent identically worded e-mail inquiries to 1115 Los Angeles-area landlords (Carpusor & Loges, 2006). The researchers varied the ethnic connotation of the sender’s name and tracked the percentage of positive replies (invitations to view the apartment in person). “Patrick McDougall” “Said Al-Rahman” and “Tyrell Jackson” received, respectively, 89 percent, 66 percent, and 56 percent invitations. (In this experiment, what was the independent variable? The dependent variable?)
A key goal of experimental design is validity, which means the experiment will test what it is supposed to test. In the rental housing experiment, we might ask, “Did the e-mail inquiries test the effect of perceived ethnicity? Did the landlords’ response actually vary with the ethnicity of the name?”
Experiments can also help us evaluate social programs. Do early childhood education programs boost impoverished children’s chances for success? What are the effects of different antismoking campaigns? Do school sex-education programs reduce teen pregnancies? To answer such questions, we can experiment: If an intervention is welcomed but resources are scarce, we could use a lottery to randomly assign some people (or regions) to experience the new program and others to a control condition. If later the two groups differ, the intervention’s effect will be supported (Passell, 1993).
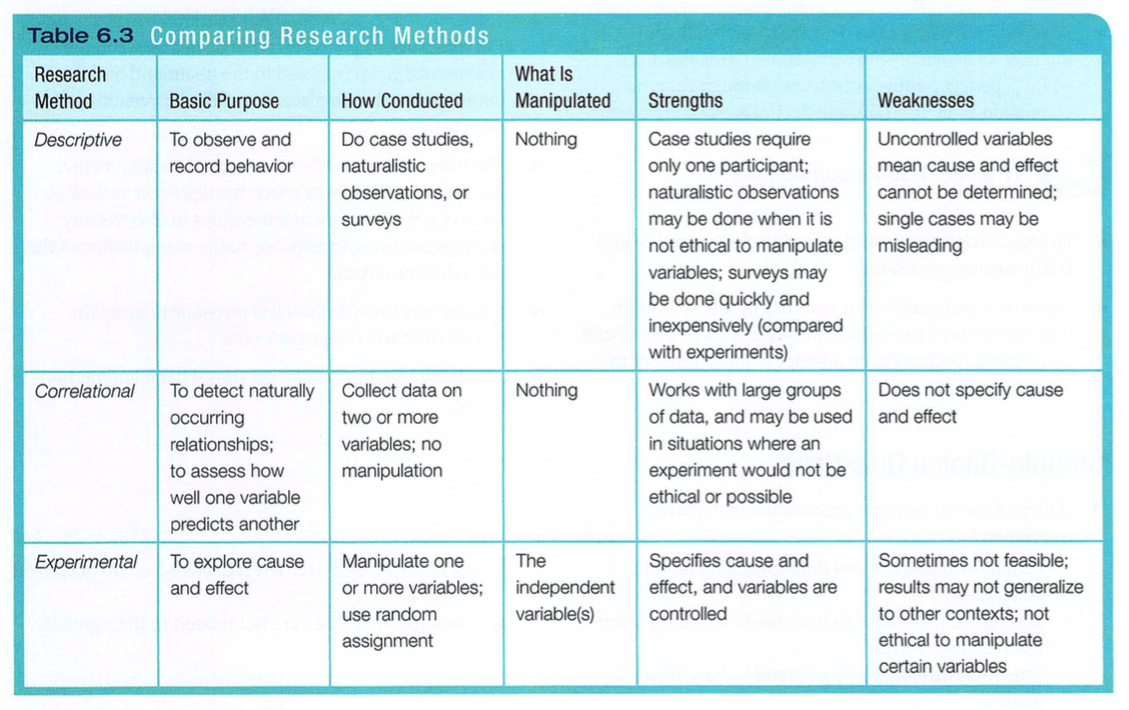
Let’s recap. A variable is anything that can vary (infant nutrition, intelligence, TV exposure-anything within the bounds of what is feasible and ethical). Experiments aim to manipulate an independent variable, measure the dependent variable, and allow random assignment to control all other variables. An experiment has at least two different conditions: an experimental condition and a comparison or control condition. Random assignment works to equate the groups before any treatment effects occur. In this way, an experiment tests the effect of at least one independent variable (what we manipulate) on at least one dependent variable (the outcome we measure). TABLE 6.3 compares the features of psychology’s research methods.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}